
Three theses on AI value capture
Implications for Middle Powers

Luis Garicano and Jesús Saa-Requejo1
The leading AI labs and their investors are spending hundreds of billions of dollars on one main bet: that whoever holds the most capable model captures the value the technology creates. Almost every decision in Silicon Valley follows from it. Read through the lens of the economics of industrial organisation, it looks like the wrong bet to us.
The model layer is sandwiched between customers who can instantly switch providers and suppliers who are each monopolists in their layer. The three theses below explain why we believe that, and why the surplus is likely to flow past the labs to the layers above and below them.
Value capture will take place both at the top of the value chain, the hardware and physical providers, and in the implementation layer, where models are put to work and where the binding constraint is organizational, not technical.
In a context of enormous uncertainty, the best strategy for middle powers to retain value from AI implementation is to endow themselves with optionality and flexibility by forming a coalition to pool their money and talent into a shared open model aiming to be one or two steps behind the frontier, not in order to win the model race but to keep that race competitive.
Thesis 1. Competition in the output market will remain intense
The first thesis that we want to put forward here is that the labs are and will remain involved in a fierce race to be profitable. The reason is that it will be difficult for them to lock in customers. The profitability for most of the previous generation of software companies relied on network effects, which are large in business-to-business and business-to-consumer platforms. Facebook works because of direct network effects: my friends are on Facebook so I cannot leave.
Analogous network effects hold for Booking.com, Uber or even Microsoft. An API call to a language model has none of these properties. It sends tokens to a model and receives tokens back. Switching providers is a configuration change, and, at least, the data necessary for fine-tuning and the finetuned model always stays with the corporate user.
Meanwhile, token prices are kept down by fierce competition between the frontier labs. If they were to implicitly cooperate and aim to significantly raise them, with nothing to stop a customer from switching, many consumers could switch to less capable models.
In other words, the competitive fringe of open weight models places a ceiling on the ability of frontier models to raise prices. The most used Chinese model, MiniMax M2.5, is priced at $1.15 per million output tokens against $25 for Claude Opus 4.6.
True, agentic AI is changing the world. How much would you be willing to pay not to lose access to the frontier model? How much will companies be willing to pay? Value creation is enormous. But willingness to pay is not the price. Intense competition on comparable capability leads to most of the new value being captured by users as consumer surplus rather than by the labs as revenue. As the figure below shows the distance between models at the frontier remains small.
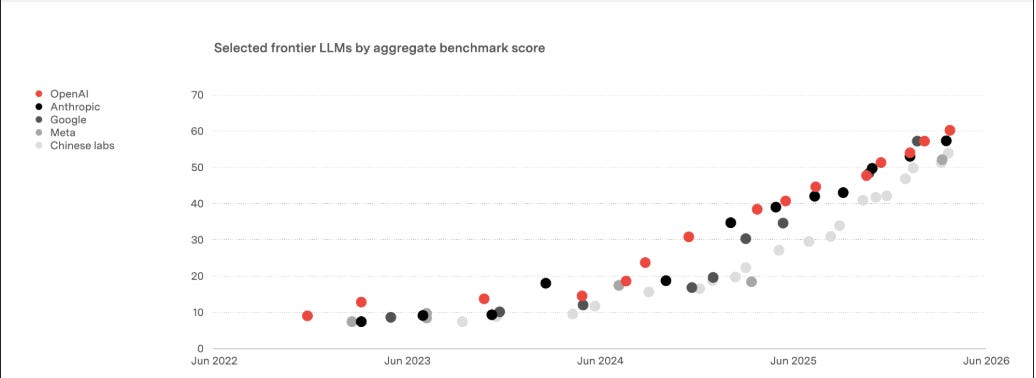
Source: Artificial Analysis, Benedict Evans 2026.
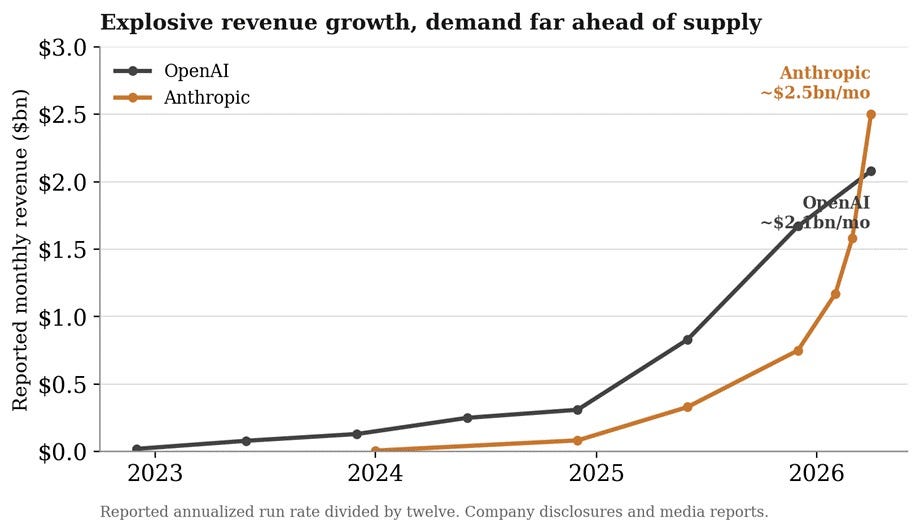
We are not arguing that the labs cannot turn a profit. Anthropic has today told investors it expects second-quarter revenue of $10.9 billion, more than double the $4.8 billion it earned in the first quarter, and a first operating profit of around $559 million. But the labs can sell enormous volumes of tokens and still see the margins compressed. It is too early to give too much weight to the revenue and profitability profiles as these are early days in the adoption process. In any case two qualifiers apply to today’s disclosure: the WSJ reports the company expects to return to losses later in the year and “it is unclear what accounting methods Anthropic used to book revenues and costs.”
The figures hide a larger structural problem. Even when inference becomes profitable, the incentives are for the labs to invest back every dollar into the next training run in order to stay ahead. The cost of doing that run keeps increasing: Epoch AI estimates that the cost of training a frontier model has risen about 2.4 times a year since 2016. They cannot stop and harvest, that is the logic of the race. And when the growth slows down, the rest catch up. This has been an old trap for innovators. The classic case is EMI, which invented the CT scanner in the early 1970s. Its chief engineer won the Nobel prize in 1979. By 1980 it had to be rescued, because all the revenue it had made from its invention was ploughed back into staying ahead.
There is a favorable case for the labs: they could exploit learning curves, the mechanism that allowed Google to beat Microsoft on search in a context where network effects were absent: more searches produced better results, which produced more searches. Two things may qualify the extrapolation of this mechanism to the future of AI. First, the fine-tuning data that improves a deployed model is in the customer’s servers, not in the lab, and corporate use agreements usually bar the labs from training on it. Second, Google’s edge came from a large gap in search scale as its search data was much larger than Microsoft’s already by 2008, whereas the size in gap between frontier labs and the open-weight models is much smaller.
All in all, though, we don’t rule that this mechanism may end up working for certain types of implementation, coding being one candidate. Recursive self-improvement, where the model improved itself, is the extreme case of this. But we argue that where users retain full control over their proprietary data, like for machine tools manufacturing, it will be difficult for AI Labs to be the beneficiaries of these learning curves.
Thesis 2. The upstream bottleneck is concentrated and powerful, and likely to remain so
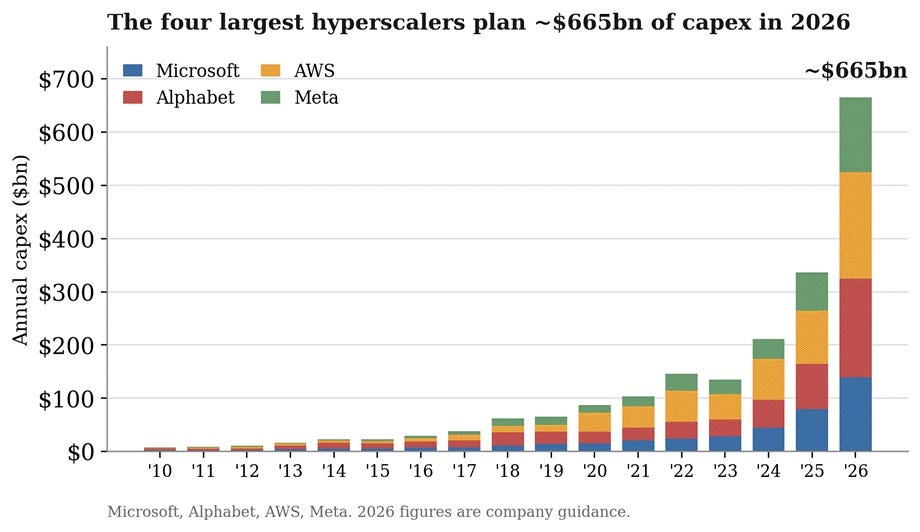
A March 2026 SemiAnalysis Substack post documents that TSMC’s N3 wafer capacity has become the binding constraint on AI growth. AI accelerators absorb 9 percent of N3 output in 2025, are projected to take 60 percent in 2026, and 90 percent in 2027. Hyperscaler capex consensus for 2026 was revised up to 665 bn for the main four hyperscalers (see figure below). On-demand GPU prices are rising even for older Hopper chips. Here the lock-in that is absent at the model layer is very clear: Nvidia and the hyperscalers have multi-year contracts at TSMC and with the memory suppliers that new entrants cannot replicate in a reasonable time frame.
The puzzle is why Nvidia and TSMC ration wafers and orders rather than clearing the market through price. The answer is that they are maximizing usage, investing in growing the market to collect revenue tomorrow. At the moment, the shadow price of frontier compute is dramatically higher than the contracted price, and the rents are flowing to TSMC, to the memory oligopoly (SK Hynix, Samsung, Micron), and to Nvidia as the architect of the entire supply chain.
Thesis 3. Intelligence is not the bottleneck
In most applications, the marginal increase in model capability buys a small marginal increase in value. Claude Code is amazing for coding, but coding is only a small part of the economy. Intelligence is not what stops most organisations from doing what they want to do. AI changes the cost of processing information, which is rarely the binding constraint. But the scarce input in most of the “messy work” required to implement autonomous AI is not IQ, but the workflow redesign, organizational authority, proprietary data, and the political ability to overcome resistance. The marginal product of moving from a model six months old to today’s frontier release is small relative to any of them. This is the thesis of Messy Jobs, the book Luis is publishing with Jin Li and Yanhui Wu on June 15.
Suppose a tax authority wants to use AI to flag suspected fraud. The frontier model can review past files, cross-reference declarations, and identify anomalies. None of this is the binding constraint today. The binding constraint is that every adverse decision must be legally justified and subject to appeal. Existing models can do much of the empirical analysis already, and the gain from upgrading them is real but not large. The constraints lie elsewhere.
This has long been true in the adoption of new technologies. The path is difficult and slow, and the returns flow to those able to implement the technology. The United States spent twenty-seven billion dollars under the HITECH Act starting in 2009 to digitize hospital records. More than a decade later, physicians spend roughly half their day on completing those records and about a quarter with patients. The technology was available; the knowledge of how to use it was not. The Stanford AI Index 2026 finds AI agent deployment in the single digits as a share of activity across nearly all business functions, even after two years of saturation coverage. No frontier model fixes that.
The result is that the implementation layer captures value through its organizational ability to take advantage of the new technology and redesign the workflows effectively. It is here, in the implementation stage, that regulation plays a crucial role in determining the legal environment that prevents incumbents from blocking or resisting adoption.
Lessons for middle powers
In the short run, the constraint on the global AI economy is not models or applications but chip production, a problem being solved by companies in the United States, Taiwan, Korea, and Japan as well as Germany and the Netherlands in what concerns the capital equipment to make the chips (ASML and Zeiss). In the long run, to the extent that the model layer is kept competitive, a large part of the surplus flows to the implementation layer.
If our theses are correct and European firms succeed at AI implementation, the surplus will be captured in the implementation layer. This success would not require that Europe build a frontier model, but using a capable model, rebuilding work around it and taking care of organizational and regulatory binding constraints.
But this implementation strategy requires that the model layer stays competitive. Europe and other middle powers cannot take the risk that the future may turn differently. A coalition of middle powers could fund a shared, open weights model held one or two tiers behind the frontier to guarantee the intensity of competition the implementation strategy needs.2
Having an alternative model provides them with a very valuable option under radical uncertainty against the two riskiest scenarios: that the frontier keeps racing and access is rationed or weaponised; and that a single provider tries to lock in the market. In the other scenarios, the shared cluster becomes ordinary infrastructure.
Is this feasible? If the goal was to develop a frontier model, the answer would probably be negative. Even with almost unlimited resources, Meta and xAI are finding it hard to keep up with the frontier. But if the goal is to build an open weights one or two tiers behind the frontier, the project is probably affordable. The United States private sector invested $286 billion in AI in 2025, and will invest 3 times as much this year; China one twentieth of that, $12.4 billion.
The Silicon Valley argument is that access to the frontier will be rationed, and that countries on the wrong side of the rationing will fall behind. We believe that the country that wins is not the one with the freshest tokens. It is the one that has done the unglamorous work of reorganising itself to use what is already available.
A “CERN for AI” has been proposed in some form and name by both von der Leyen’s political guidelines and the Letta and Draghi reports. The Centre for Future Generations published a detailed institutional blueprint for it. Our vision here differs from the CGH version whose purpose is to trustworthy general-purpose AI and it treats open weights as the first stage and closes the model as it becomes more capable. Our theses point the other way. The institution should aim one or two tiers behind the frontier, not at it and should keep its weights open by default.
As one of the co-authors of the CERN for AI piece you cite, I've definitely moved away from a publicly-funded effort to directly compete with labs at the frontier, but I'm also sceptical of strategies that rely on open models.
At the very least, Chinese open models appear to be falling further and further behind the frontier: https://www.nist.gov/news-events/news/2026/05/caisi-evaluation-deepseek-v4-pro
It looks like Chinese models are misreporting their evaluation results and have inflated performance as a result -> when independently evaluated, the gap is increasing between the frontier and open models.
Unclear how much of this is because of intense compute shortages. Regardless, seems like Europe should be building more compute.
I agree with your take on why the model layer won't capture value—and it maps directly onto something I've been working on about why different countries are optimizing for different AI finish lines.
Your three theses explain why the pattern observed empirically makes economic sense. The US is racing toward engagement and platform value (model layer), but as you point out, that layer is sandwiched between monopolist hardware suppliers and customers with zero switching costs. Meanwhile, China has been optimizing for exactly what you're prescribing for Europe: deployment in the implementation layer where org design, not IQ, is the binding constraint.
In my piece, I explored why America builds AI for attention (girlfriends, viral moments) while China wires it into factories, hospitals, and power grids. Your thesis 3—"intelligence is not the bottleneck"—is the theoretical foundation for why China's deployment track will capture more value than America's model-layer race. The marginal gain of moving from GPT-4o to GPT-5.2 is small compared to redesigning a hospital workflow or integrating AI into injection-molding quality control.
https://rajeshachanta.substack.com/p/spectacle-vs-scaffolding
So, China is way ahead in executing the "smart second mover" strategy you recommend for Europe. Their progress confirms you don't need frontier models to deploy effectively—you need good-enough models plus org capacity and a willingness to experiment.
Can Europe imitate the China path? Yes but only if Europe can build the org and regulatory capacity to execute on implementation when they don't have China's state coordination or America's VC density.